The head of product development was asking this question to my boss. This happened during my second week in the new office.
The below graph is interactive. The data underneath is not the one that I used 6 years ago. I also recreated the visualization using the test runs on the AWS free tier. However, you may get the same touch and feel of what my audience got six years ago by interacting with these visualizations.
“Rajesh will lead from now on”. This was my boss, the head of IT Architecture.
Although, this was just my second week, I was not new to such situations. Being a consultant in the past, I have had experiences being in the middle of firefighting on the second or third day of starting a new work.
Still, I was trying my best to cope up with several events that unfolding that day such as the lead developer submitting his resignation earlier that day. I also heard that head of IT operations and one of the business heads met with CEO and convinced him to outsource the analytics platform that I was hired to manage.
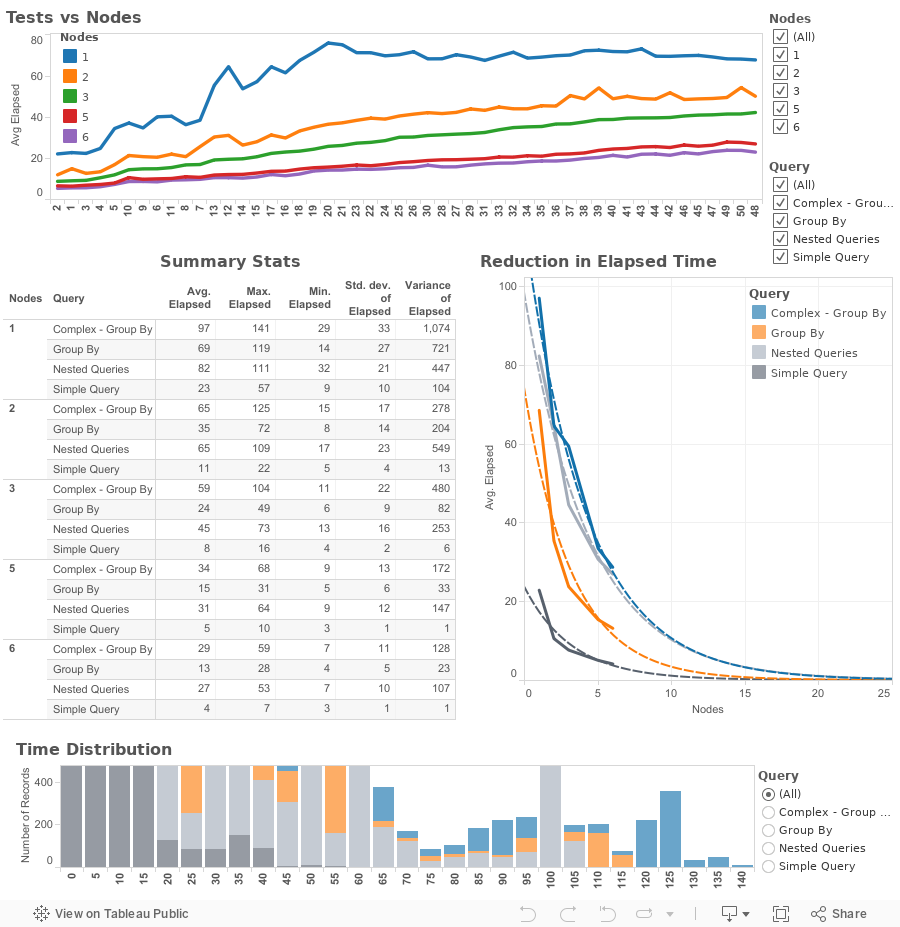
The lead developer had written a script in the R language. He was the only one in the company who knew the internals of Hadoop and R at that time. His R code was also expected to generate performance charts. These graphs were supposed to answer how many Hadoop data nodes needed for the BigData project
These charts, unfortunately, did not help the team to get the results they were looking for. The results were not consistent between executions. In addition, it did not predict the future requirements the IT head wanted.
The direction I got from my new boss was to work with this lead developer to understand the code and execution procedures before he leaves. The short-term goal was to get the growth factor to support our estimated load for the next 18 months as quickly as possible.
The on-demand and elastic nature of cloud offerings were not a topic for discussion during our design considerations due to security constraints.
The development lead was going to be in the office for one more day. But, that next day was a Friday! “Wish me good luck,” I told myself.
My boss needed an answer by Tuesday, which was just 4 days away if I also counted the weekend.
I met with the lead developer the next day, but before I could ask for help, he started saying.
“Raj, unfortunately, I don’t have time to go through this now. I have a meeting with HR.” He then wrote down his cell number on a piece of paper and rushed out. “You can call me if you have any questions about the code or the setup next week.” He did not forget to apologize before leaving.
I wasn’t new to R. In fact, I had been using R for almost 2 years by then. What I did not know, being new to this office, the hidden valleys and trenches the on-premise infrastructure typically keeps in its sleeve. There was nothing written down about where and how to run this code.
The next day, an operation team member who had worked on getting the Hadoop ecosystem running with the lead developer approached me. He and I worked together to devise a plan on how to go about performing the simulation tests. This was the beginning of a great friendship that grew until I left this company five years later.
I had to make some changes first to the R code. This change was needed to make some parallel threads function correctly. I also tweaked the code to simplify its execution and run it the way we wanted. I channeled the output from R to Tableau so that we can build the visualization in Tableau. This helped to introduce the interaction and prediction features that were missing from the previous charts.
With the help of my new friend, we were able to spin off a couple of new VMs. I installed the R server on them and integrated that with Tableau QA servers. I had to write some extra code on the R side to do some aggregation to support the integration work that we had planned for this task.
We kicked off the R batch job. My friend started monitoring the Hadoop ecosystem using the Cloudera admin GUI. We had some cleansing work to do on a couple of backend data servers after each run. We also had to make sure that the log data was versioned and safe on the backend servers for our graph processing.
He kept adding a new data node each time after our run. We repeated the execution of the code on the new setup. Once we hit our maximum nodes limit available in our environment, we started the reverse procedure. This time, instead of adding, he started decommissioning one data node at a time after each run.
We decided to do this reverse procedure to compare and contrast the same configurations for two runs at two different times to track the fluctuations.
We met with the team and presented the above interactive visualization on Tuesday.
“Great teamwork!” The Head of IT then turned towards me. “Rajesh, can you send me the links to these visualizations?